计网笔记-数据链路层1
开头👴先抄一个gzc的思维导图: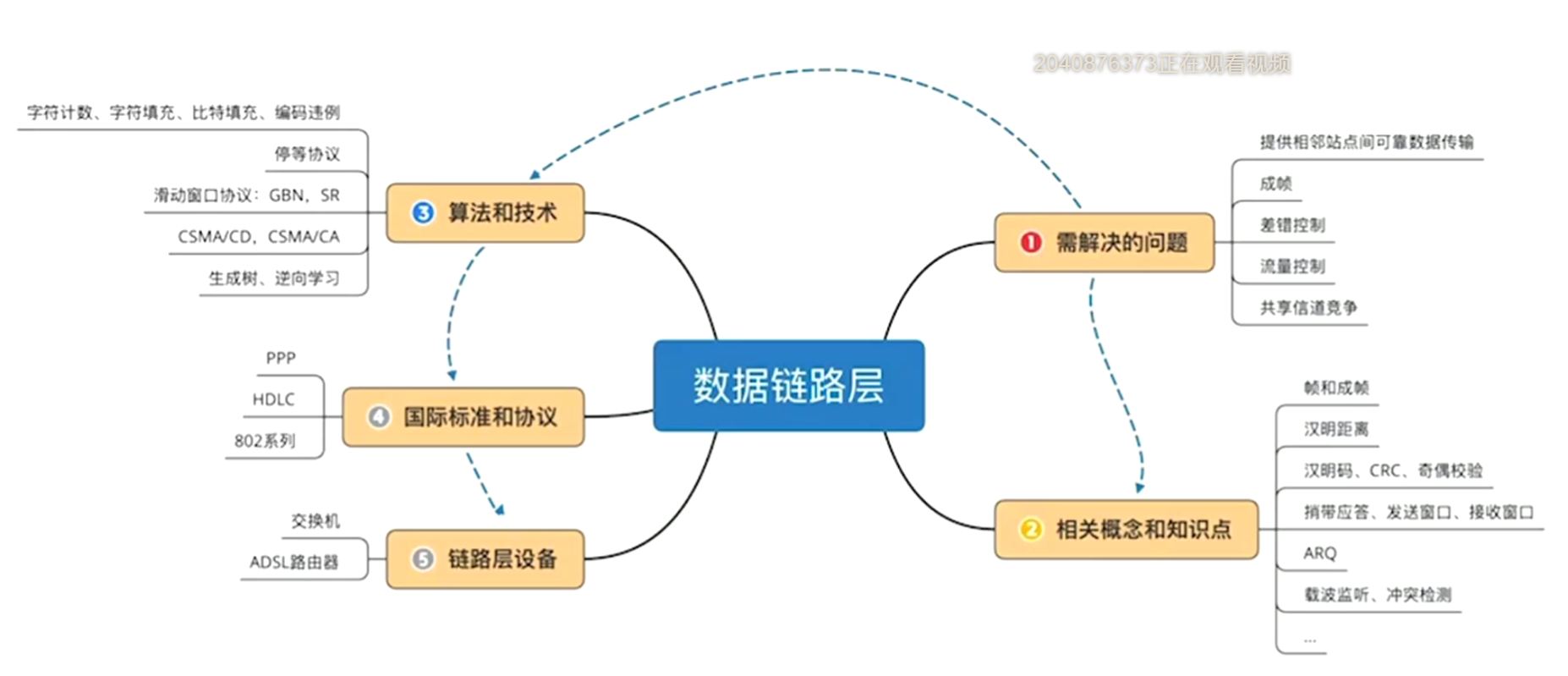
3.1数据链路层的设计问题
3.1.1提供给网络层的服务
数据链路层的功能
- 向网络层提供一个定义良好的服务接口。
- 处理传输错误。
- 调节数据流,确保慢速的接收方不会被快速的发送方淹没。
提供给网络层的服务
Unacknowledged connectionless service.
Most LANs局域网 use unacknowledged connectionless serviceAcknowledged connectionless无连接的,也就是不用事先建立通路 service.
This service is useful over unreliable channels, such as wireless systems。给一个ACK,有确认的服务Acknowledged connection-oriented service
- Connection establishment - Timer - Sequence number 若ACKnumber丢了,防止重复
当使用面向连接的服务时,数据传输必须经过三个不同的阶段。在第一个阶段,要建立连接,双方初始化各种变量和计数器,这些变量和计数器记录了哪些帧已经接收到,哪些帧还没有收到。在第二个阶段,才真正传输一个或者多个数据帧。在第三个也是最后一个阶段中,连接被释放,所有的变量、缓冲区以及其他用于维护该连接的资源也随之被释放。
3.1.2成帧Framing
字符计数
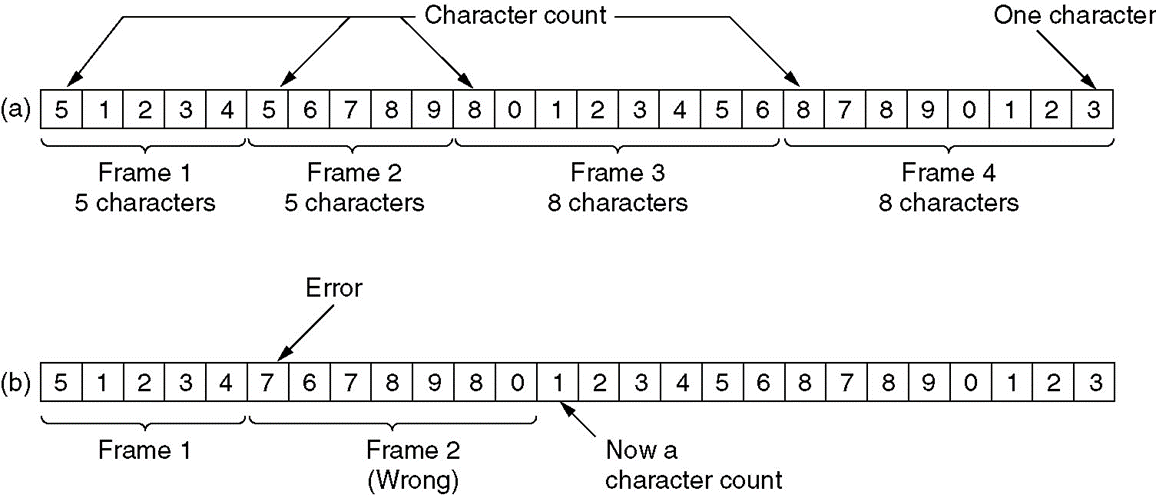
一旦出错:运气不好的话所有的帧都不能正确识别
字符填充法(byte stuffing)
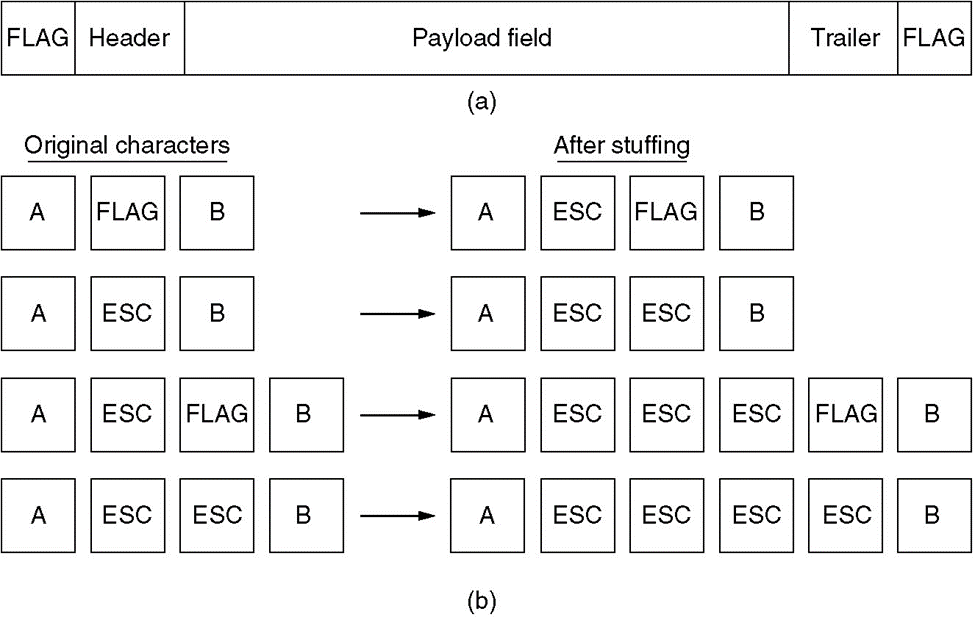
帧标志出错了:每两个帧之间至少有一个帧标志,仅影响当前帧。
问题:发送的信息含有很多控制字符,需要转译的字符大大增加
开销:overhead,跟需要发送的数据相比,额外添加的转义字符所占的比例,比如全是需要转译的字符的信息,overhead就是100%。
比特填充(bit stuffing)
每个帧的开头结尾都是一个special bit pattern, 01111110 ,也就是16进制的7EH,当数据内容出现连续的1时,每遇到五个1添加一个0(硬件不管这5个1后面是0还是1),接收方做相反的工作。另外在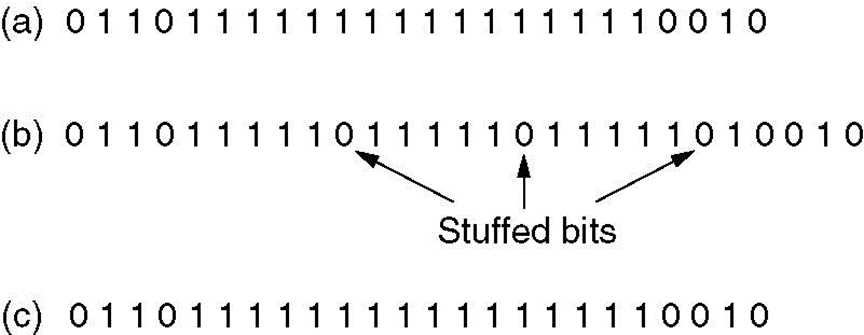
(a) The original data.
(b) The data as they appear on the line.
(c) The data as they are stored in receiver’s memory after destuffing.
就是每隔五个1插入一个0
物理层编码违例
Physical layer coding violation (n. 违反, 冒犯, 侵害)
对于曼彻斯特Manchester编码,两个跳变表示一个bit,所以当出现长高电平,常低电平,就属于物理层违例了,可以作为帧的边界。
3.1.3差错控制(ERROR control)
可靠的传输:不能少,不能多,顺序不能错
3.1.4流量控制
两种流量控制
- 基于反馈信息的流量控制 feedback
- 基于速率的流量控制(主要是网络层,一种内嵌的机制,浅显的理解是限制速率)rate-based
流量控制协议
- 停等 Stop Aan Wait
- 滑动窗口 Sliding Window
3.2差错检验和纠正
错误分类
- lost frames:一个数据帧完全没能传过去,常常是因为噪音或者掉队
- damaged frames:一些bit错了
差错检测
- 奇偶校验码(parity):检测单比特错误
- Cyclic Redundancy Check:CRC
- Atuomatic Repeat reQuest:ARQ
差错纠正
- 前向纠错(forward error correction)FEC
纠错码
补充:海明距离Hamming
两个编码异或之后为1的位数
检测到d个errors,需要distance为d+1的编码
纠正d个errors,需要distance为2d+1的编码
这里的距离指的是码表上任意两个编码之间的hamming距离,取最小。对于已知的检错方法,要确定能够检测出几个error应该考虑最坏的情况。
海明码
一个公式:
$m+r+1 \le 2^r$
m:数据位数
r:所需的校验位
由该式可以解出需要的最少校验位
海明码的构造:
为什么这个人字这么难看啊吐…大概是自己也知道不会再看第二遍了吧…(orz)
海明码的作用:
可以校验一位差错,并纠正。
假如第5位发生了错误,那么第1和4位的校验位会出错,计算1+4可得第5位出错,取反即可纠正。而如果是校验位发生了错误,那么只有那一个校验位错了,就可以知道是校验位出错了。(所有这些都是建立在仅仅发生一个bit的错误上的)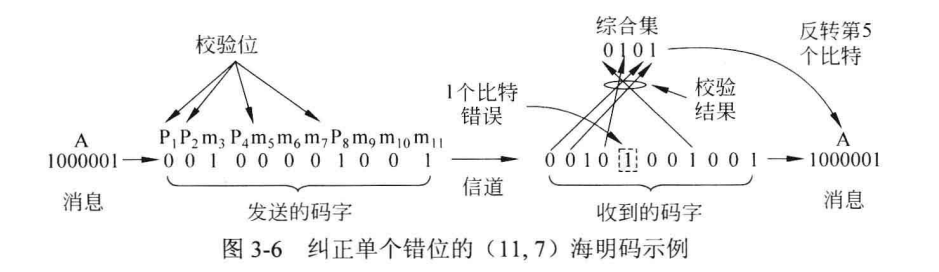
如果发生了多位差错呢?
correct burst errors:
这里👴没懂具体咋搞的,回头机缘巧合懂了再来补文字解释(🕊🕊🕊咕咕咕)
其他的一些纠错码:
卷积码(convolutional code)
里德所罗门码(Reed-Solomon code)
低密度奇偶校验码(Low-Density Parity Check codes)
检错码
关于用检错码划算还是用纠错码划算的问题:
gzc给了一个Example
(single-bit error)
- 比特错误率 BER=10-6, 1Block=1000bits, Data=1M bits,也就是说传1M($10^6$)的数据,每1000bits分一个块块er,然后一共有1000个块块er。
- The overhead(开销)
- 检错码Error detection + retransmission: 2001 bits (1000+1001)多的那个1是重传的时候的奇偶校验位啦(
- 纠错码Hamming code : 10,000 bits(1000块*10位校验位)
一道👴不理解的题
Suppose that data are transmitted in blocks of sizes 1000 bits. What is the maximum error rate under which error detection and retransmission mechanism (1 parity bit per block) is better than using Hamming code? Assume that bit errors are independent of one another and no bit error occurs during retransmission.
奇偶校验码Parity
略
校验和Checksums
gzc说从网上抄了段代码给👴们👀👀
1 | Word Cksum(Word *Buf, Word Num_Words) |
CRC循环冗余校验
这玩意儿是个重点
名字:Ploynomial code多项式编码,也就是CRC
计算CRC:
Frame:要传输的数据帧
Generator:生成多项式,可以和二进制串一一对应,(一般第一位是1)如$x^4+x+1$对应串10011,最高幂次r=4,对应r+1=5位二进制串,从低位开始写不容易出错。
在计算过程中的法则是模2加法,也就是异或运算,在该运算中,加减等价。
计算过程:
- 把Frame左移r位,也就是$\times2^r$
- 用(1)得到是数模二除Generator(注意这个过程所有的加和减也都是异或运算)
- 除到(1)得到的数的最后一位得到余数,用(1)中数-余数,但是这里也是模二减,相当于异或“+”,且不产生进位er。
- 如果最终得到的余数不是刚好r位:就直接当数加上去的,详见例2.
- 然后算完之后就看gcz说的power,👴就发现,加上余数之后恰好整除Generator
一个例子1:
例子2: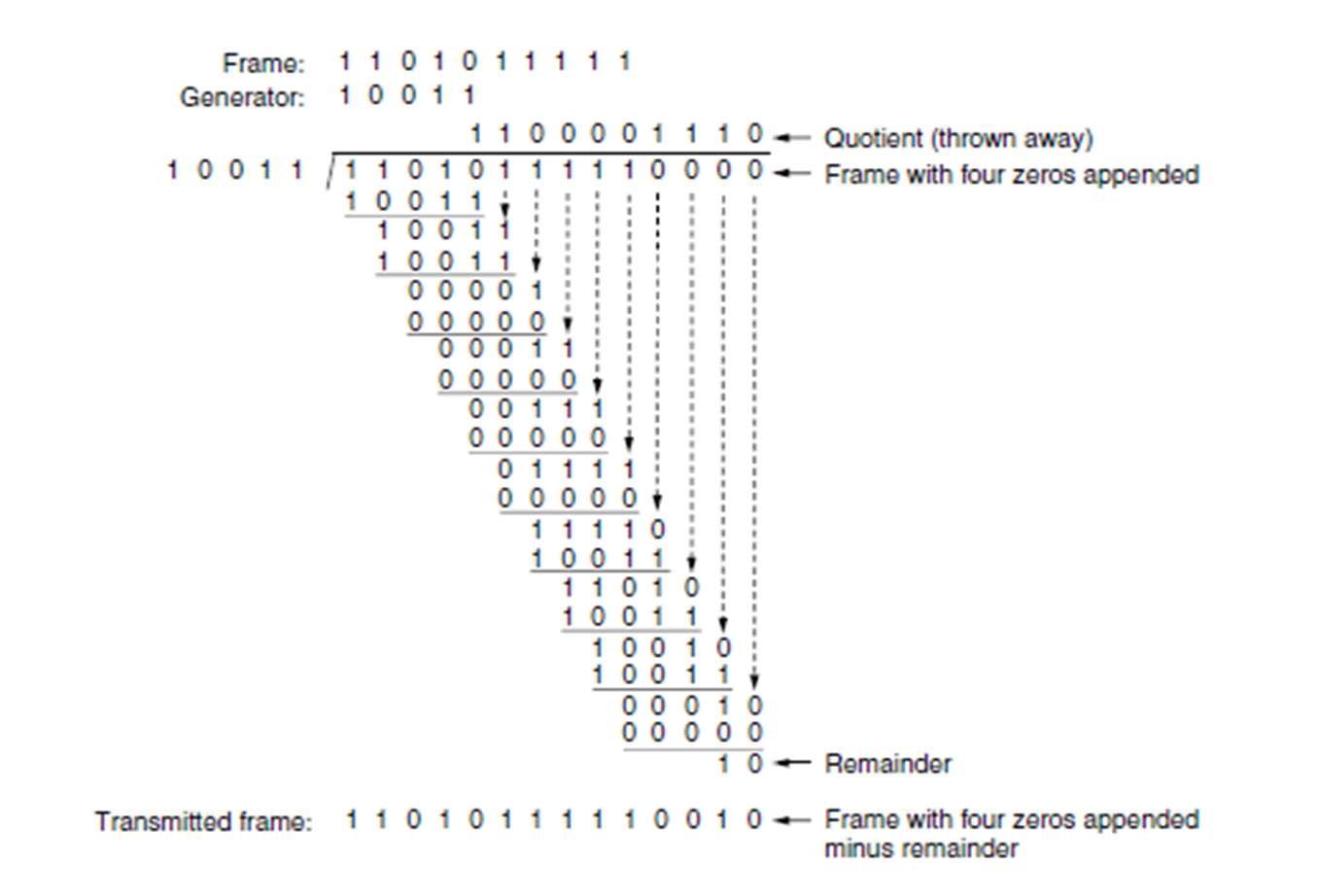
the power of CRC
- 若不出现差错:收到T(X)
- 若出现了一些差错:收到E(X),由于模二加法,0->1和1->0都可以用“+”表示
- 计算[T(X)+E(X)]/G(X) = E(X)/G(X),所以在E(X)/G(X)==0的时候,差错不能被检查出来
- 由此推论:
- 添加了r bit的冗余信息的码,一定能检测出$\le r$bit的差错,因为rbit冗余信息意味着最高幂次为r,也就是说G(X)有r+1位。
- 若让(x+1)是G(X)的一个因子(factor),则所有的奇数位都可以检测出来,这玩意儿可以证,但根据速通理论的高质高效原则,👴忍住了,没去看怎么证。
- 若触发差错的bits长度为(r+1),则检测不出来的概率为$\cfrac{1}{2^{r-1}}$,因为出错长度为r+1个bit,则第一个和最后一个一定是错了也就是E(X)的第一位和最后一位都是1,而剩下的中间r-1位不知道是0(没错)还是1(错了)。
- 而若触发差错的bits长度更长的时候,触发差错的可能就是$\cfrac{1}{2^r}$
生成多项式:
- CRC-16
$x^{16}+x^{15}+x^2+1$- CRC-CCITT (HDLC)
$x^{16}+x^{12}+x^5+1$- CRC-32 (IEEE802)
$x^{32}+x^{26}+x^{23}+x^{22}+x^{16}+x^{12}+x^{11}+x^{10}+x^{8}+x^{7}+x^{5}+x^{4}+x^{2}+x^{1}+1$
3.3基本(elementary)数据链路层协议
几种单工协议:
An Unrestricted Simplex Protocol 乌托邦,Unrestricted没有限制的
A Simplex Stop-and-Wait Protocol 停等协议
A Simplex Protocol for a Noisy Channel 噪音
Protocol 1: 乌托邦Utopia
无差错的channel,完美的接收者,源源不断的发送
Protocol 2:停等协议
Stop-and-Wait Protocol for a Error-free Channel
考虑flow control,仍然是完美的信道
↑对于短距离的通信完全是没有问题的,效率很高,远距离就不行了
Protocol 3:有噪音的
A Simplex Protocol for a Noisy Channel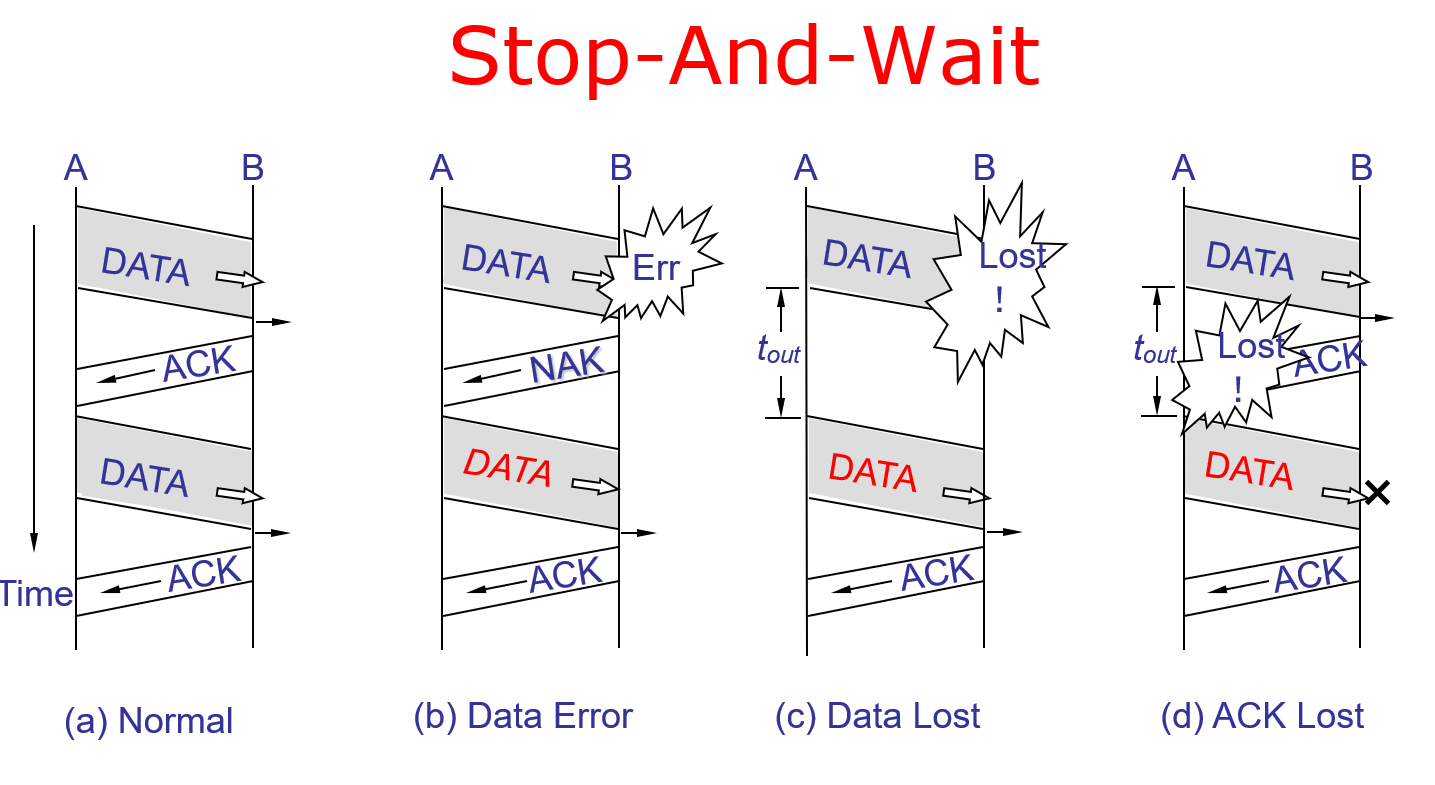
ACK:acknowledgement character命令正确应答
NAK:nagative acknowladge否定应答
前3种情况都没有问题,但是第4种,ACK丢了,就可能导致重复发送,这就引入了序列号的使用。
此外,一个晚到的ACK也可能导致发送重复的数据
Sequence Number
对于数据链路层的停等协议,一个bit(0/1)就足够了,可以做到判断是新的还是旧的帧
对于传输层,1bit就不够了,需要较大的编号空间使得在编号回卷时,保证同编号的旧帧不可能被缓冲在网络中,如:TFTP
protocol3:
- sender 伪代码
课本上的代码见这里
1 | 从网络层获取一个分组放入buffer |
简化版:
1 | 从网络层获取一个分组放入buffer |
- receiver伪代码
课本上的代码见这里
1 | frame_expected=0 |
计时器Timer
gzc说计时器的间隔是个比较精细的活儿,短了可能收不到,然后每个帧都得发俩遍,间隔长了效率低。实际上设计的比较保守(因为错误实在比较少),但是自己做的实验里面就整个比较合适的值就完了(500ms差不多就完了,这世间卫星都跑到了)。
👴居然听懂了