并行计算笔记
第一章 并行计算概述
1. 什么是并行计算
2. 并行问题与并行计算模型
BSP模型 是整体同步并行计算模型
适用用于初学者
整体程序分为大的几个同步模块,每个模块里面尝试并行
每个模块里面要干的事情就是 局部计算,通信和同步
补充:编程分为哪三个部分?
输入 计算 输出
并行编程模型
- 共享存储模型
- 线程模型
- 消息传递模型
- 数据并行模型
常见的并行编程模型/语言
- 消息传递以及MPI
- OpenMP
- 分区全局地址空间(Partitioned Global Address space PGAS),是把上面俩的好处结合起来了
什么是CUDA
CUDA: Compute Unified Device Architecture(计算统一设备架构)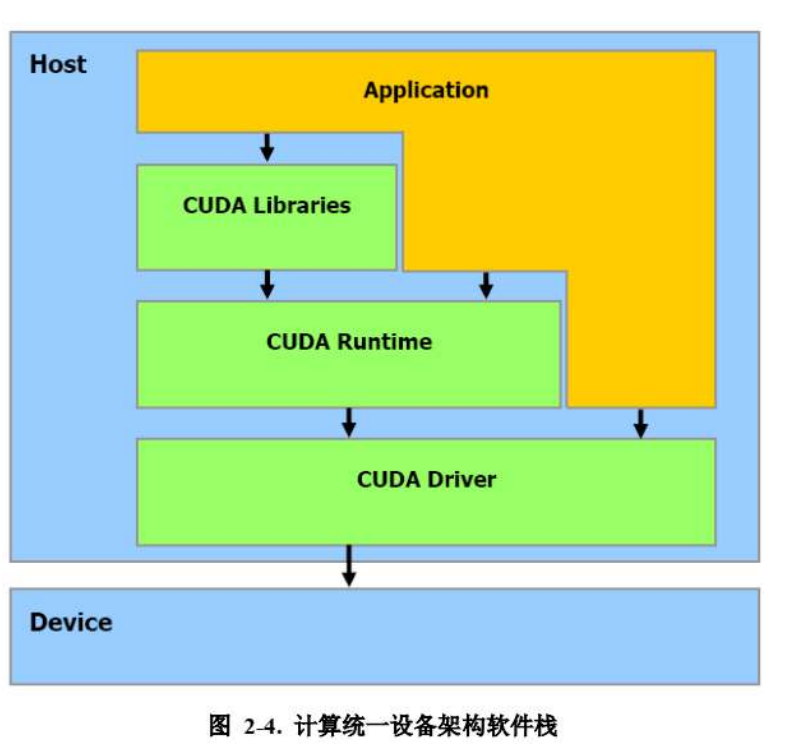
大多数的开发者,用的是Cuda Runtime的API
CUDA Libraries 又叫CUDAx,是为了满足各行各业的加速需求出现的更简单的封装接口
设计并行处理程序和系统
- 自动和手动并行
- 理解问题和陈鼓型
- 分块分割
- 通信
- 同步
- 数据依赖
- 负载均衡
- 粒度
- I/O
- 成本
- 性能分析和优化
本机GPU
NVIDIA GeForce RTX 3060 Laptop GPU
官网详细信息
第二章
CPU与GPU之间的数据传输
cudaMalloc
该函数从设备内存中分配size字节的空间地址给devPtr。传递的时候要将devPtr的地址传递进去
1 | cudaError_t cudaMalloc(void ** devPtr, size_t size); |
cudaMallocHost() or cudaHostAlloc()
分配主机内存,这些内存是锁页的,可以被设备访问。
驱动程序跟踪用这个函数分配的虚拟内存范围,并自动加速对cudaMemcpy*()等函数的调用。
用于数据交换,或CPU与GPU之间的通讯。
用cudaMallocHost()分配过多的内存可能会降低系统性
能,因为它减少了系统可用于分页的内存量
1 | __host__ cudaError_t cudaMallocHost ( void** ptr, size_t size ) |

cudaMemcpy()
1 | __host__ cudaError_t cudaMemcpy ( void* dst, const void* src, size_t count, cudaMemcpyKind kind ) |
dst – 目的内存地址 src – 源内存地址
count – 拷贝的大小,单位为字节
kind – 传输的类型。指定了拷贝的方向,取值如下: cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost, cudaMemcpyDeviceToDevice, or cudaMemcpyDefaut
推荐使用cudaMemcpyDefault, 这种情况下,传输的类型由指针的取值推测处理。
cudaMemcpyToSymbol()
1 | template<class T> |
kind 取值可能为udaMemcpyHostToDevice, cudaMemcpyDeviceToDevice, or udaMemcpyDefault.
将src指向的内存区域的计数字节,复制到符号symbol开始的偏移字节所指向的内存区域。这些内存区域不能重叠(在DeviceToDevice时)。
symbol是一个驻留在设备全局或设备常量内存空间中的变量。
cudaMemcpyFromSymbol()
1 | template < class T > |
1 | int main() |